这篇文章是第四篇也是ECC:基本介绍(ECC: a gentle introduction.)系列的最后一篇
在上一篇文章中我们看到了两个算法,ECDH和ECDSA,我们看到了椭圆曲线离散对数问题如何在这两个算法的安全性上扮演重要的角色。但是,如果你记得,我们说过对于离散对数问题的复杂度我们目前没有数学证明:我们相信它是“困难”的,但是我们并不确定。在这篇文章的第一部分,我们将尝试用当前的技术去解读这个问题在实践中的“难度”。
然后在第二部分我们将尝试解答这个问题:为什么RSA(以及其他基于模数运算的密码系统)表现良好的情况下我们还需要椭圆曲线密码。
破解离散对数问题
我们现在要看椭圆曲线离散对数问题中两个最高效的算法: baby-step,giant-step算法和 Pollard’s rho method。
在开始之前,再回顾一下,这是离散对数问题的定义:**给定两个点P和Q,找到一个整数x满足等式Q=xP。**这个点在一个基点为G阶为n椭圆曲线的子群中。
Baby-step, giant-step
在介绍这个算法的细节之前,快速思考一下:我们总是能把任意x写成x=am+b,这里a,m和b是三个任意的整数。例如,我们能写出10=2*3+4.
考虑到这点,我们可以把离散对数问题重写成如下:
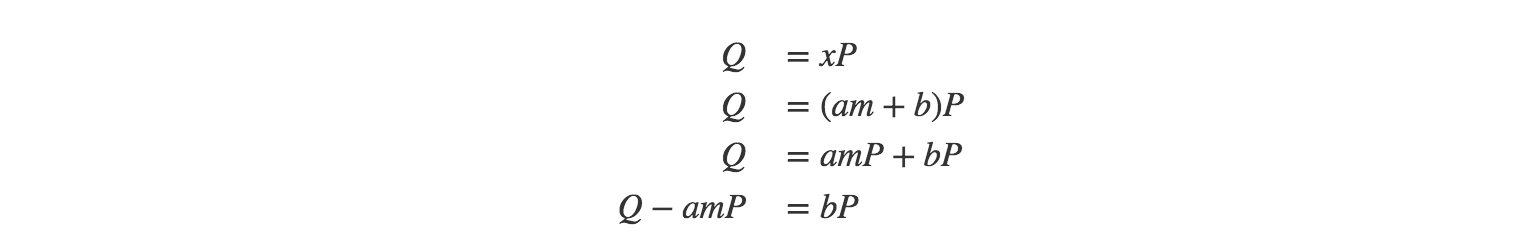
baby-step giant-step是“中间相遇”算法.和暴力破解(迫使我们计算每一个x的xP值,知道找到Q)相反,我们将计算少量bP的值和少量Q-amP直到我们找到相似。这个算法工作原理如下:
- 计算m=⌈√‾n⌉
- 对每一个0…m的b,计算bP并把值存入一个哈希表
- 对与每一个0…m的a:
- 计算amP;
- 计算q-amP
- 检查哈希表看是否存在点bP满足Q-amP=bP;
- 如果点存在,那么我们就找到了x=am+b。
正入你看到,开始我们用少量增长(“baby”)的系数b(1P, 2P, 3P, …)计算了点bP,在算法的第二部分我们用大量增长(“giant”)的am(1mP, 2mP, 3mP, …,这里m是一个很大的数)计算了amP。
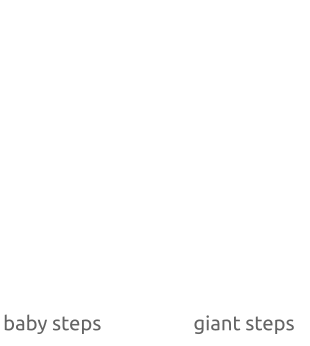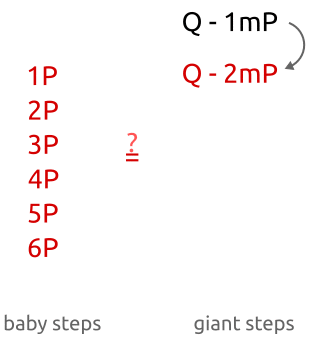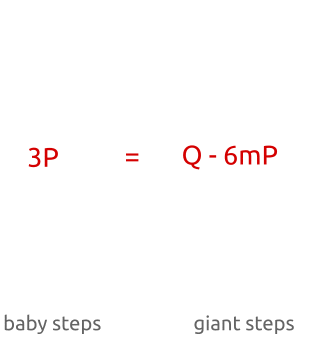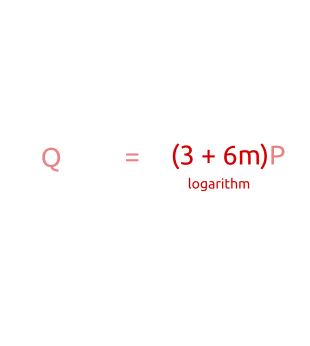
baby-step, giant-step算法开始我们用很少的步骤计算了少量的点,把它们存入一个哈希表。然后我们执行了大量运算并且用新的点和哈希表中的点做了对比。一旦找到一个匹配,计算离散对数就是一个重写排列问题。
要理解为什么这个算法有效,暂时忘掉点bP被缓存,注意力放在Q=amP+bP。考虑以下内容:
- 当a=0我们检查Q是否等于bP,这里b是0到m的一个数。这样,我们用Q和0P到mP比较。
- 当a=1我们检查Q是否等于mP+bP。我们用Q和mP到2mP比较。
- 当a=2我们用Q和2mP到3mP比较。
- …
- 当a=m-1,我们用Q和所有(m-1)mP到m^2P=nP比较。
总结起来,我们检查所有0P到nP的点(这是所有的点),执行最多2m次加法和乘法(正常的m是baby次,最大m是giant次)。
如果假设查找一次哈希表花费O(1)时间,很容易得到这个算法的时间和空间复杂度都是是0(√‾n)(或者考虑比特长度为O(2^k/2))。这依然是指数时间,但比暴力破解好多了。